Explaining async/await in 200 lines of code
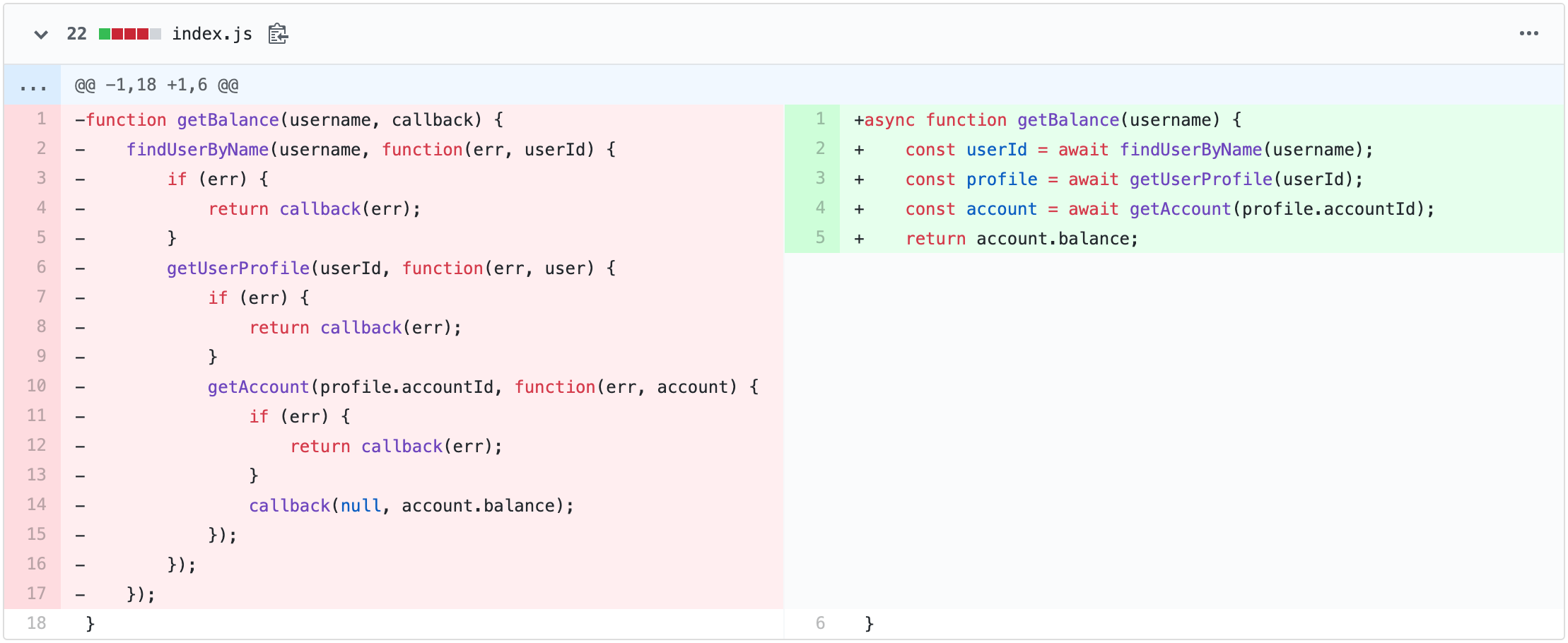
In the previous article, we learned how to implement a simple but workable event loop. However, programs which are supposed to be run by the event loop are full of callbacks. This is the usual problem of event-loop-driven environments. When business logic becomes reasonably complicated, callbacks make program's code hardly readable and painfully maintainable. And the callback hell begins! There is plenty of ways to deal with the artificial complexity arose due to callbacks, but the most impressive one is to make the code great flat again. And by flat, I mean callback-less and synchronous-like. Usually, it's done by introducing async/await syntactic feature. But every high-level abstraction is built on top of some basic and fundamental ideas. Let's check the async/await sugar out and see what exactly happens under the hood.